Das Gesamtbild
Was steckt hinter der Projektstruktur – und warum ist sie für Data Analytics besonders wertvoll?
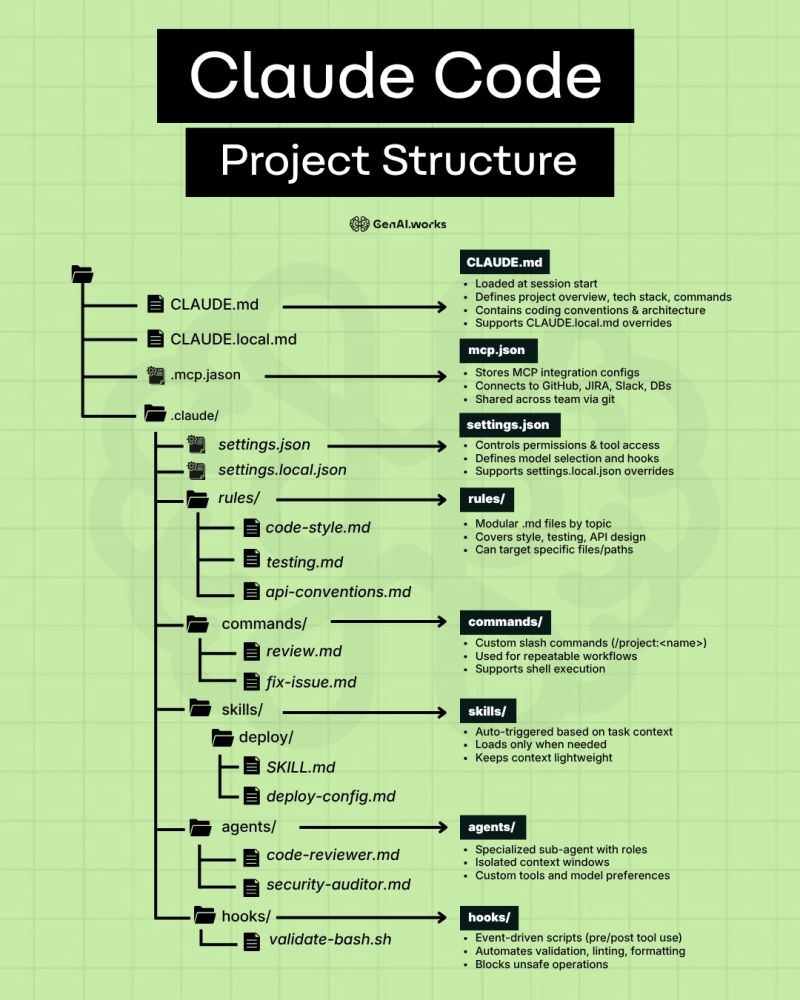
Claude Code liest beim Start einer Session automatisch CLAUDE.md – das ist das Projekt-Briefing, das Claude sagt, worum es geht, welche Tools erlaubt sind und wie der Code aussehen soll. Alle weiteren Dateien verfeinern dieses Wissen: Rules liefern Stil, Commands automatisieren Workflows, Skills laden nur bei Bedarf, Agents delegieren Teilaufgaben, Hooks verhindern Fehler.
Für Data Analytics ist diese Struktur Gold wert: Einmal korrekt aufgesetzt, kennt Claude dein gesamtes Datenschema, deine SQL-Dialekte, Python-Konventionen und Reporting-Standards – ohne dass du es jedes Mal neu erklären musst.
🎯 Kernprinzip
- Einmal konfigurieren, dauerhaft profitieren
- Kontext wird nicht bei jeder Frage neu erklärt
- Teams arbeiten identisch – kein „bei mir funktioniert's anders"
- Claude versteht dein Projekt wie ein Kollege, der dabei war
📊 Für Data Analytics
- Tabellenstruktur & Primärschlüssel einmalig dokumentieren
- SQL-Dialekt (BigQuery vs. Postgres vs. DuckDB) festlegen
- Naming Conventions für Metriken & Dimensionen
- dbt-Modelarchitektur & Layer-Konventionen
CLAUDE.md – Das Projekt-Briefing
Die wichtigste Datei. Wird bei jedem Session-Start automatisch geladen.
Claude liest diese Datei automatisch beim Start jeder Session. Sie ist dein dauerhafter Kontext – kein erneutes Erklären nötig. Für Data Analytics hier: Datenquellen, Schema-Überblick, verwendete Tools, Konventionen.
✅ Was rein gehört
- Projektziel in 2–3 Sätzen
- Tech Stack (Python 3.11, dbt 1.7, BigQuery)
- Wichtigste Tabellen & Beziehungen
- Coding-Konventionen (snake_case, type hints)
- Verbotene Operationen (kein DELETE ohne WHERE)
⚠️ Was NICHT rein gehört
- Passwörter, API-Keys (→ .env)
- Sehr lange Tabellenbeschreibungen (→ rules/)
- Spezifische Workflow-Steps (→ commands/)
- Alles über 500 Zeilen (→ aufsplitten!)
# Analytics Platform – Projekt-Kontext ## Stack & Umgebung - Python 3.11 · pandas, polars, sqlalchemy, dbt 1.7 - Datenbank: Google BigQuery (Projekt: `acme-analytics-prod`) - BI-Tool: Looker (LookML) · Reporting: Jupyter + nbconvert - Versionierung: GitHub · CI/CD: GitHub Actions ## Datenmodell-Überblick # Schichten (dbt layers) raw/ → Rohdaten, nie direkt abfragen staging/ → 1:1 Abbilder, Typen gecasted, keine Joins intermediate/ → Business-Joins, berechnete Felder marts/ → Fertige Reporting-Tabellen (fact_*, dim_*) ## Wichtigste Tabellen - `marts.fact_orders` PK: order_id, FK: customer_id, product_id - `marts.dim_customers` PK: customer_id, SCD Typ 2 - `marts.dim_products` PK: product_id, Hierarchie: category→subcategory ## Coding-Konventionen - SQL: snake_case, CTEs bevorzugen, keine Subqueries in FROM - Python: type hints Pflicht, docstrings bei jeder Funktion - Metriken immer als Float, nie gerundet in der Quelle - Datumsfelder: immer UTC, Format YYYY-MM-DD ## Sicherheitsregeln NIEMALS: DELETE/TRUNCATE ohne explizite Bestätigung NIEMALS: Direkt auf raw-Layer joinen IMMER: Queries mit LIMIT testen, dann ohne
CLAUDE.local.md ergänzt CLAUDE.md für deine persönlichen Präferenzen, wird aber nicht ins Git committed – ideal für lokale Pfade, persönliche Shortcuts oder Team-unabhängige Settings.Äquivalent in OpenAI Codex CLI
Unterschiede
- Codex nutzt
AGENTS.mdstatt CLAUDE.md als Primärdatei - Zusätzlich:
.cursorrules(Cursor IDE) odersystem_prompt.md - Kein automatisches Laden – muss explizit referenziert werden
- Kein CLAUDE.local.md Äquivalent out-of-the-box
Parallelen
- Beide laden beim Start einen persistenten Projekt-Kontext
- Beide unterstützen Markdown-Formatierung
- Beide empfehlen Tech-Stack, Konventionen und Verbote zu dokumentieren
- Beide können hierarchisch (global + lokal) konfiguriert werden
.mcp.json – Tool-Integrationen
Verbindet Claude mit externen Diensten: DBs, APIs, Issue-Trackern
Model Context Protocol (MCP) ist der offene Standard, mit dem Claude Code auf externe Tools zugreift – direkt aus dem Terminal, ohne Copy-Paste. Für Data Analytics: Datenbankabfragen, GitHub-Issues, Jira-Tickets, Slack-Benachrichtigungen.
{
"mcpServers": {
"bigquery": {
"command": "mcp-server-bigquery",
"env": { "GOOGLE_PROJECT_ID": "acme-analytics-prod" }
},
"github": {
"command": "mcp-server-github",
"env": { "GITHUB_TOKEN": "${GITHUB_TOKEN}" }
},
"dbt-cloud": {
"command": "mcp-server-dbt",
"env": { "DBT_CLOUD_API_KEY": "${DBT_CLOUD_API_KEY}" }
},
"slack": {
"command": "mcp-server-slack",
"env": { "SLACK_BOT_TOKEN": "${SLACK_BOT_TOKEN}" }
}
}
}
🔍 Was Claude damit kann
- Live-Abfragen gegen BigQuery stellen ohne Terminal-Wechsel
- GitHub Issues anlegen wenn ein Bug im Code gefunden wird
- dbt-Jobs triggern und auf Completion warten
- Slack-Nachricht senden wenn ein Report fertig ist
- API-Secrets aus Umgebungsvariablen – nie im Code!
Äquivalent in OpenAI Codex CLI
Unterschiede
- Codex CLI nutzt OpenAI's Function Calling statt MCP
- Tool-Konfiguration über
codex.jsonoder CLI-Flags - MCP-Standard ist noch nicht nativ integriert (Stand 2025)
- Weniger vorgefertigte Server verfügbar
Parallelen
- Beide können externe Dienste via Tools anbinden
- Beide unterstützen Env-Variable für Secrets
- Beide haben wachsende Ökosysteme an Integrationen
- MCP wird von mehreren Anbietern unterstützt (Anthropic-Initiative)
settings.json – Berechtigungen & Modell
Was darf Claude tun? Welches Modell? Hooks aktivieren?
Steuert fein granular, welche Tools Claude verwenden darf – ohne Rückfrage, mit Rückfrage oder gar nicht. settings.local.json überschreibt diese Werte lokal (z.B. für Entwickler mit mehr Rechten).
{
"model": "claude-sonnet-4-6",
"permissions": {
"allow": [
"Bash(python:*)", // Python uneingeschränkt
"Bash(dbt:*)", // dbt-Befehle erlaubt
"Bash(git:*)", // Git-Operationen ok
"Read(**)", // Alle Dateien lesen
"Write(models/**)", // Nur im models/-Ordner schreiben
"mcp__bigquery__query" // BigQuery-Abfragen erlaubt
],
"ask": [
"Bash(psql:*)", // DB-Zugriff: immer fragen
"Write(seeds/**)" // Seed-Daten: fragen
],
"deny": [
"Bash(rm:*)", // Löschen verboten
"Bash(*:*DELETE*)" // SQL DELETE verboten
]
},
"hooks": {
"PreToolUse": [".claude/hooks/validate-sql.sh"],
"PostToolUse": [".claude/hooks/log-queries.sh"]
}
}
rules/ – Modularisierte Coding-Standards
Thematisch aufgeteilte Regeln, die Claude immer kennt
Rules sind modulare Markdown-Dateien, die Claude's Verhalten für bestimmte Dateitypen oder Ordner präzisieren. Der Vorteil: CLAUDE.md bleibt schlank, spezifische Regeln gelten nur wo sie gebraucht werden.
# SQL Coding Standards ## Gilt für: `models/**/*.sql`, `analyses/**/*.sql` ## Formatierung - Keywords GROSSGESCHRIEBEN (SELECT, FROM, WHERE) - Jede Spalte in eigener Zeile - CTEs immer benennen (nicht inline) - Alias immer mit AS keyword ## Verboten - SELECT * (immer explizit) - Subqueries in FROM-Klausel - CROSS JOIN ohne explizite WHERE ## BigQuery-Spezifisch - Partitioned Tables immer mit _PARTITIONTIME filtern - ARRAY_AGG statt GROUP_CONCAT - Backticks für Project.Dataset.Table
# Python Analytics Standards ## Gilt für: `notebooks/**`, `scripts/**` ## Imports - pandas as pd, numpy as np (Standard) - polars bevorzugen bei >1M Zeilen - matplotlib.pyplot as plt ## DataFrames - Keine inplace=True Operationen - Methodenketten mit \ umbrechen - Kopien explizit: df.copy() ## Dokumentation - Jede Funktion: Input-Typen, Output-Typ - Magic Numbers als Konstanten - Datenquellen im Notebook-Header
## Gilt für:-Direktive (oder globs: in der settings.json) gelten Regeln nur für bestimmte Ordner. Dbt-Models bekommen SQL-Regeln, Notebooks bekommen Python-Regeln.commands/ – Eigene Slash-Befehle
Wiederholbare Workflows mit einem Befehl starten
Jede .md-Datei in diesem Ordner wird zu einem Custom Slash-Command: /project:review-model, /project:fix-pipeline. Für Data Analytics sind das die wertvollsten Automatisierungen.
# dbt Model Review Reviewe das aktuelle dbt-Model (`$ARGUMENTS` oder aktuell geöffnete Datei). Prüfe folgende Punkte und erstelle einen strukturierten Report: ## 1. Datenqualität - Sind alle Primärschlüssel eindeutig (dbt test unique)? - Gibt es not_null Violations auf wichtigen Feldern? - Prüfe auf mögliche Duplikate durch fehlende DISTINCT ## 2. Performance - Werden Partitionen korrekt genutzt (_PARTITIONTIME)? - Gibt es unnötige Full Table Scans? - Können CTEs durch Materialisierung beschleunigt werden? ## 3. Code-Qualität (prüfe gegen .claude/rules/sql-style.md) - SELECT * vorhanden? - Alle Joins mit expliziten Bedingungen? - Kommentare bei komplexer Business-Logik? ## Output-Format Erstelle eine Tabelle: | Issue | Severity | Fix | Severity: 🔴 Kritisch / 🟡 Warnung / 🟢 Hinweis
# Neue Metrik erstellen Erstelle eine neue Business-Metrik für `$ARGUMENTS`. ## Schritte 1. Lese `models/marts/` um bestehende Tabellen zu verstehen 2. Erstelle `models/marts/metrics/metric_$ARGUMENTS.sql` 3. Folge dem Template in `models/_templates/metric_template.sql` 4. Erstelle passende Tests in `tests/metrics/` 5. Füge Beschreibung in `models/marts/schema.yml` hinzu 6. Führe `dbt compile --select metric_$ARGUMENTS` zur Validierung aus Frage VOR dem Erstellen: Wie soll aggregiert werden (SUM/AVG/COUNT)? Welcher Zeitraum ist relevant?
skills/ – Lazy-Loading Workflows
Werden nur geladen wenn gebraucht – spart Kontext und Tokens
Skills unterscheiden sich von Commands: Sie werden automatisch geladen wenn Claude erkennt, dass sie relevant sind – anhand der Beschreibung im SKILL.md-Header. Der Trick: Der Header wird immer gelesen (3 Zeilen), der Rest nur bei Aktivierung.
# EDA Report Skill ## Use when: User wants to explore a dataset, understand distributions, find anomalies ## Do NOT use for: Production pipeline code, model creation, SQL optimization ## Workflow 1. Lade die Datei/Tabelle und zeige .info(), .describe(), .head() 2. Fehlende Werte: Heatmap + prozentuale Übersicht 3. Numerische Spalten: Histogramme + Outlier-Detection (IQR-Methode) 4. Kategorische Spalten: Value Counts + Top-10 Bar Charts 5. Korrelationsmatrix (Spearman für robustere Ergebnisse) 6. Zeitreihen: Trend, Saisonalität, Breaks identifizieren 7. Erstelle Summary-Markdown mit Key Findings ## Output-Format - Jupyter Notebook mit klaren Abschnittstiteln - Jede Visualisierung mit Interpretation (2–3 Sätze) - Finale Empfehlungen: Was braucht Aufmerksamkeit?
🎯 Weitere nützliche Skills für Data Analytics
- dbt-debug/ – Automatisch testen, Fehler diagnostizieren, Fixes vorschlagen
- sql-optimize/ – Query-Plan analysieren, Partitionierung verbessern, Kosten senken
- report-generator/ – Daten → Markdown-Report mit Visualisierungen
- data-quality/ – Vollständigkeit, Konsistenz, Aktualität prüfen
- looker-lml/ – LookML für neue Explores/Dimensions schreiben
agents/ – Spezialisierte Sub-Agenten
Eigenständige Agenten für komplexe Teilaufgaben mit isoliertem Kontext
Agents sind spezialisierte Sub-Agenten, die Claude für bestimmte Aufgaben aufruft. Jeder Agent hat ein eigenes Kontextfenster, eigene Tools und eigene Persönlichkeit. Besonders mächtig für Parallelisierung.
--- name: data-quality-auditor description: Prüft Datensätze auf Qualitätsprobleme. Trigger: "datenqualität", "anomalien", "data quality", "überprüfe die daten" model: claude-haiku-4-5 # Schnell & günstig für repetitive Checks tools: [Read, Bash, mcp__bigquery__query] --- Du bist ein Datenqualitäts-Spezialist. Deine Aufgabe: ## Prüfkatalog 1. Vollständigkeit: NULL-Raten pro Spalte, Pflichtfelder 2. Eindeutigkeit: Duplikate in PK-Feldern, doppelte Transaktionen 3. Konsistenz: Referentielle Integrität, FK-Verletzungen 4. Aktualität: Letzte Aktualisierung, Freshness-Checks 5. Plausibilität: Negative Beträge, Zukunftsdaten, Outlier >3σ ## Output Erstelle immer einen Data Quality Score (0-100) mit Begründung. Liste Issues nach Severity geordnet mit SQL-Queries zur Verifikation.
🤖 Weitere Analytics Agents
- sql-reviewer – Prüft alle SQL-Files im PR auf Standards
- metric-validator – Vergleicht Metriken gegen historische Werte
- documentation-writer – Schreibt dbt-Dokumentation aus Models
- security-auditor – Prüft auf PII in Query-Ergebnissen
⚡ Parallelisierung
- Mehrere Agents gleichzeitig auf verschiedene Tabellen loslassen
- Haiku für schnelle/günstige Tasks, Opus für komplexe
- Jeder Agent hat isolierten Kontext – kein „Vergessen"
- Ergebnisse werden an Haupt-Claude zurückgemeldet
Agents in Codex CLI
Unterschiede
- Codex hat kein natives agents/-Ordner-Konzept
- Sub-Agents über OpenAI Assistants API manuell gebaut
- Kein automatischer Model-Wechsel pro Agent (Haiku/Opus)
- Tool-Berechtigungen pro Agent nicht konfigurierbar
Parallelen
- Beide unterstützen Multi-Agent-Architekturen
- Beide können spezialisierte Sub-Tasks delegieren
- Beide basieren auf demselben ReAct-Prinzip
- AutoGen/CrewAI funktioniert mit beiden Backends
hooks/ – Automatische Validierung
Pre/Post-Tool-Skripte: validieren, loggen, blocken
Hooks sind Shell-Scripts, die automatisch vor oder nach jedem Tool-Aufruf laufen. Für Data Analytics sind sie unverzichtbar: Verhindern teurer BigQuery-Scans, loggen alle Datenbankabfragen, validieren SQL bevor es ausgeführt wird.
#!/bin/bash # Wird VOR jeder Bash-Ausführung aufgerufen # Stoppt gefährliche SQL-Operationen COMMAND="$1" # Blocke DELETE/TRUNCATE/DROP ohne Bestätigung if echo "$COMMAND" | grep -iE "(DELETE|TRUNCATE|DROP TABLE)"; then echo "⛔ BLOCKED: Destructive SQL operation detected" echo "Reason: DELETE/TRUNCATE/DROP requires manual confirmation" exit 1 # Exit 1 = Claude darf NICHT ausführen fi # Warne bei BigQuery Full Table Scans (kein Partition-Filter) if echo "$COMMAND" | grep -i "FROM \`acme" | grep -v "_PARTITIONTIME"; then echo "⚠️ WARNING: Query may scan full table (no partition filter)" echo "Estimated cost: potentially high. Add _PARTITIONTIME filter." # Exit 0 = erlaubt aber mit Warnung fi exit 0
#!/bin/bash # Loggt alle ausgeführten Befehle für Audit-Trail TIMESTAMP=$(date +"%Y-%m-%d %H:%M:%S") COMMAND="$1" LOG_FILE=".claude/logs/query-audit.log" mkdir -p .claude/logs echo "[$TIMESTAMP] $COMMAND" >> "$LOG_FILE" # Bei dbt-Ausführungen: Ergebnis in Slack posten if echo "$COMMAND" | grep -q "dbt run"; then curl -s -X POST "$SLACK_WEBHOOK" \ -d '{"text":"🔄 dbt run executed by Claude Code: '"$COMMAND"'"}' fi
Gesamtvergleich: Claude Code vs. OpenAI Codex
Wo sind die echten Unterschiede – und wo kann man Erfahrungen übertragen?
OpenAI Codex CLI (veröffentlicht 2025) ist das direkteste Pendant zu Claude Code – beide sind Terminal-basierte KI-Coding-Assistenten. Viele Konzepte überlappen, aber die Implementierungsdetails unterscheiden sich erheblich.
✅ Klare Vorteile Claude Code für Analytics
- MCP → direkte BigQuery/Snowflake/Postgres-Verbindung out-of-the-box
- Skills reduzieren Token-Verbrauch bei repetitiven EDA-Tasks erheblich
- Agents mit Haiku für billige Datenqualitätschecks, Opus für komplexe Analysen
- Hooks blockieren destruktive SQL-Operationen zuverlässig
- CLAUDE.md + rules/ = Claude kennt Schema dauerhaft
⚡ Klare Vorteile Codex für Analytics
- o3/o4-mini besser bei mathematisch-statistischen Reasoning-Tasks
- Stärkere Container-Sandbox: sicherer für produktionskritische Umgebungen
- Bessere Jupyter-Notebook-Integration (experimentell aber aktiv entwickelt)
- OpenAI-Ökosystem: nativer ChatGPT-Zugang für Nicht-Techniker im Team
🔄 Was sich 1:1 übertragen lässt
- CLAUDE.md → AGENTS.md: Gleiche Inhalte (Stack, Schema, Konventionen), nur Dateiname ändert sich
- rules/-Konzept → System-Prompt-Anhänge: Gleiche Modularisierungs-Idee, andere Umsetzung
- MCP-Server Wissen → Function Calling: Gleiche Integrationsziele, unterschiedliche Protokolle
- Hooks-Logik → Codex Sandbox-Regeln: Beide verhindern gefährliche Operationen
- Data Analytics Prompting-Strategien: Identisch – Claude und Codex reagieren auf gleiche gute Prompts gut